CVPR 2017最佳论文DenseNet,论文中提出的DenseNet(Dense Convolutional Network) 。
作为CVPR2017年的Best Paper, DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing(梯度消失)问题的产生.结合信息流和特征复用的假设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文.
随着CNN网络层数的不断增加,gradient vanishing和model degradation(模型退化)问题出现在了人们面前,BatchNormalization(批规范化)的广泛使用在一定程度上缓解了gradient vanishing的问题,而ResNet和Highway Networks通过构造恒等映射设置旁路,进一步减少了gradient vanishing和model degradation的产生.Fractal Nets通过将不同深度的网络并行化,在获得了深度的同时保证了梯度的传播,随机深度网络通过对网络中一些层进行失活,既证明了ResNet深度的冗余性,又缓解了上述问题的产生. 虽然这些不同的网络框架通过不同的实现加深的网络层数,但是他们都包含了相同的核心思想,既将feature map进行跨网络层的连接.
优点
- 减轻了vanishing-gradient(梯度消失)
- 加强了feature的传递
- 更有效地利用了feature
- 一定程度上较少了参数数量
设计理念
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L层的网络,DenseNet共包含(L(L+1))/2个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。


如果用公式表示的话,传统的网络在 L 层的输出为:
而对于ResNet,增加了来自上一层输入的identity函数:
在DenseNet中,会连接前面所有层作为输入:
其中,上面的 H~L~(.)代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里 L层与L-1 层之间可能实际上包含多个卷积层。
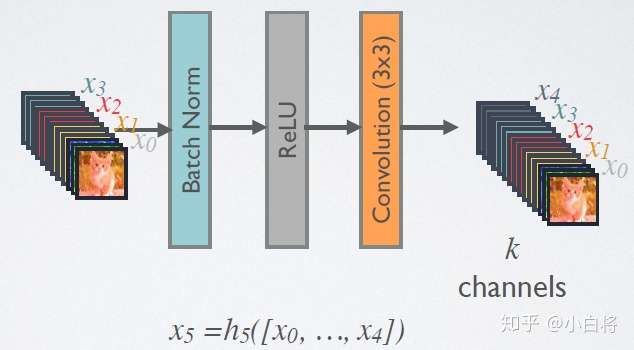
DenseNet的前向过程如图3所示,可以更直观地理解其密集连接方式,比如 h~3~ 的输入不仅包括来自h~2~ 的x~2~,还包括前面两层的 x~1~和 x~2~ ,它们是在channel维度上连接在一起的。
网络结构
如图所示,DenseNet的网络结构主要由DenseBlock和Transition组成。 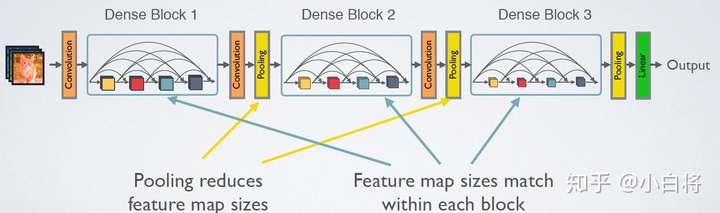
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H(.) 采用的是BN+ReLU+3x3 Conv的结构,如图所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出K个特征图,即得到的特征图的channel数为K,或者说采用K个卷积核,K在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的K(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为K~0~,那么L层输入的channel数为k~0~+k(L-1),因此随着层数增加,尽管K设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有K个特征是自己独有的。
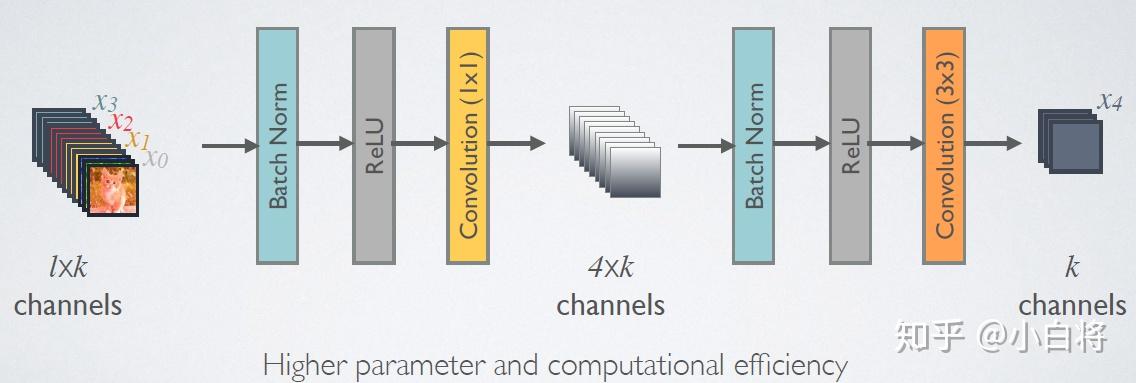
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到4K个特征图它起到的作用是降低特征数量,从而提升计算效率。
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为m,Transition层可以产生[θm]个特征(通过卷积层),其中θ∈(0,1]是压缩系数(compression rate)。当θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为32×32,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3x3卷积(stride=1),卷积核数为16(对于DenseNet-BC为2K)。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为32×32,16×16和8×8,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置:{L=40,k=12},{L=100,k=12},{L=40,k=24}。而对于DenseNet-BC结构,使用如下三种网络配置:{L=100,k=12},{L=250,k=24},{L=250,k=40} 。这里的L指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。对于普通的L=40,k=12网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。
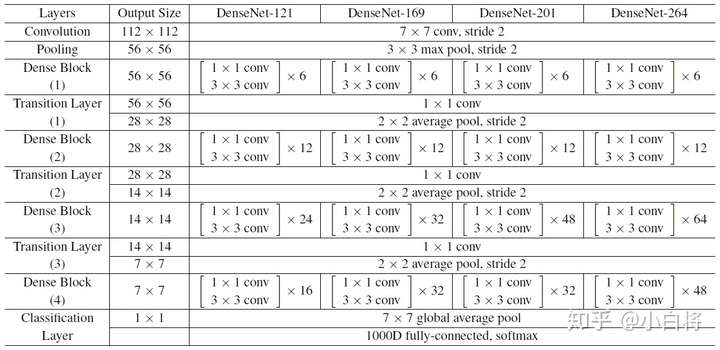
对于ImageNet数据集,图片输入大小为224×224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层(卷积核数为2K),然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表所示:
代码实现
import tensorflow as tf
from tflearn.layers.conv import global_avg_pool
from tensorflow.contrib.layers import batch_norm, flatten
from tensorflow.contrib.layers import xavier_initializer
from tensorflow.contrib.framework import arg_scope
from cifar10 import *
# Hyperparameter
growth_k = 24
nb_block = 2 # how many (dense block + Transition Layer) ?
init_learning_rate = 1e-4
epsilon = 1e-4 # AdamOptimizer epsilon
dropout_rate = 0.2
# Momentum Optimizer will use
nesterov_momentum = 0.9
weight_decay = 1e-4
# Label & batch_size
batch_size = 64
iteration = 782
# batch_size * iteration = data_set_number
test_iteration = 10
total_epochs = 300
def conv_layer(input, filter, kernel, stride=1, layer_name="conv"):
with tf.name_scope(layer_name):
network = tf.layers.conv2d(inputs=input, use_bias=False, filters=filter, kernel_size=kernel, strides=stride, padding='SAME')
return network
def Global_Average_Pooling(x, stride=1):
"""
width = np.shape(x)[1]
height = np.shape(x)[2]
pool_size = [width, height]
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride) # The stride value does not matter
It is global average pooling without tflearn
"""
return global_avg_pool(x, name='Global_avg_pooling')
# But maybe you need to install h5py and curses or not
def Batch_Normalization(x, training, scope):
with arg_scope([batch_norm],
scope=scope,
updates_collections=None,
decay=0.9,
center=True,
scale=True,
zero_debias_moving_mean=True) :
return tf.cond(training,
lambda : batch_norm(inputs=x, is_training=training, reuse=None),
lambda : batch_norm(inputs=x, is_training=training, reuse=True))
def Drop_out(x, rate, training) :
return tf.layers.dropout(inputs=x, rate=rate, training=training)
def Relu(x):
return tf.nn.relu(x)
def Average_pooling(x, pool_size=[2,2], stride=2, padding='VALID'):
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Max_Pooling(x, pool_size=[3,3], stride=2, padding='VALID'):
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Concatenation(layers) :
return tf.concat(layers, axis=3)
def Linear(x) :
return tf.layers.dense(inputs=x, units=class_num, name='linear')
def Evaluate(sess):
test_acc = 0.0
test_loss = 0.0
test_pre_index = 0
add = 1000
for it in range(test_iteration):
test_batch_x = test_x[test_pre_index: test_pre_index + add]
test_batch_y = test_y[test_pre_index: test_pre_index + add]
test_pre_index = test_pre_index + add
test_feed_dict = {
x: test_batch_x,
label: test_batch_y,
learning_rate: epoch_learning_rate,
training_flag: False
}
loss_, acc_ = sess.run([cost, accuracy], feed_dict=test_feed_dict)
test_loss += loss_ / 10.0
test_acc += acc_ / 10.0
summary = tf.Summary(value=[tf.Summary.Value(tag='test_loss', simple_value=test_loss),
tf.Summary.Value(tag='test_accuracy', simple_value=test_acc)])
return test_acc, test_loss, summary
class DenseNet():
def __init__(self, x, nb_blocks, filters, training):
self.nb_blocks = nb_blocks
self.filters = filters
self.training = training
self.model = self.Dense_net(x)
def bottleneck_layer(self, x, scope):
# print(x)
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=4 * self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[3,3], layer_name=scope+'_conv2')
x = Drop_out(x, rate=dropout_rate, training=self.training)
# print(x)
return x
def transition_layer(self, x, scope):
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
# x = conv_layer(x, filter=self.filters, kernel=[1,1], layer_name=scope+'_conv1')
# https://github.com/taki0112/Densenet-Tensorflow/issues/10
in_channel = x.shape[-1]
x = conv_layer(x, filter=in_channel*0.5, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Average_pooling(x, pool_size=[2,2], stride=2)
return x
def dense_block(self, input_x, nb_layers, layer_name):
with tf.name_scope(layer_name):
layers_concat = list()
layers_concat.append(input_x)
x = self.bottleneck_layer(input_x, scope=layer_name + '_bottleN_' + str(0))
layers_concat.append(x)
for i in range(nb_layers - 1):
x = Concatenation(layers_concat)
x = self.bottleneck_layer(x, scope=layer_name + '_bottleN_' + str(i + 1))
layers_concat.append(x)
x = Concatenation(layers_concat)
return x
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[7,7], stride=2, layer_name='conv0')
# x = Max_Pooling(x, pool_size=[3,3], stride=2)
"""
for i in range(self.nb_blocks) :
# 6 -> 12 -> 48
x = self.dense_block(input_x=x, nb_layers=4, layer_name='dense_'+str(i))
x = self.transition_layer(x, scope='trans_'+str(i))
"""
x = self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x = self.transition_layer(x, scope='trans_1')
x = self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x = self.transition_layer(x, scope='trans_2')
x = self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x = self.transition_layer(x, scope='trans_3')
x = self.dense_block(input_x=x, nb_layers=32, layer_name='dense_final')
# 100 Layer
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
# x = tf.reshape(x, [-1, 10])
return x
train_x, train_y, test_x, test_y = prepare_data()
train_x, test_x = color_preprocessing(train_x, test_x)
# image_size = 32, img_channels = 3, class_num = 10 in cifar10
x = tf.placeholder(tf.float32, shape=[None, image_size, image_size, img_channels])
label = tf.placeholder(tf.float32, shape=[None, class_num])
training_flag = tf.placeholder(tf.bool)
learning_rate = tf.placeholder(tf.float32, name='learning_rate')
logits = DenseNet(x=x, nb_blocks=nb_block, filters=growth_k, training=training_flag).model
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=label, logits=logits))
"""
l2_loss = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables()])
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=nesterov_momentum, use_nesterov=True)
train = optimizer.minimize(cost + l2_loss * weight_decay)
In paper, use MomentumOptimizer
init_learning_rate = 0.1
but, I'll use AdamOptimizer
"""
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, epsilon=epsilon)
train = optimizer.minimize(cost)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state('./model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter('./logs', sess.graph)
epoch_learning_rate = init_learning_rate
for epoch in range(1, total_epochs + 1):
if epoch == (total_epochs * 0.5) or epoch == (total_epochs * 0.75):
epoch_learning_rate = epoch_learning_rate / 10
pre_index = 0
train_acc = 0.0
train_loss = 0.0
for step in range(1, iteration + 1):
if pre_index+batch_size < 50000 :
batch_x = train_x[pre_index : pre_index+batch_size]
batch_y = train_y[pre_index : pre_index+batch_size]
else :
batch_x = train_x[pre_index : ]
batch_y = train_y[pre_index : ]
batch_x = data_augmentation(batch_x)
train_feed_dict = {
x: batch_x,
label: batch_y,
learning_rate: epoch_learning_rate,
training_flag : True
}
_, batch_loss = sess.run([train, cost], feed_dict=train_feed_dict)
batch_acc = accuracy.eval(feed_dict=train_feed_dict)
train_loss += batch_loss
train_acc += batch_acc
pre_index += batch_size
if step == iteration :
train_loss /= iteration # average loss
train_acc /= iteration # average accuracy
train_summary = tf.Summary(value=[tf.Summary.Value(tag='train_loss', simple_value=train_loss),
tf.Summary.Value(tag='train_accuracy', simple_value=train_acc)])
test_acc, test_loss, test_summary = Evaluate(sess)
summary_writer.add_summary(summary=train_summary, global_step=epoch)
summary_writer.add_summary(summary=test_summary, global_step=epoch)
summary_writer.flush()
line = "epoch: %d/%d, train_loss: %.4f, train_acc: %.4f, test_loss: %.4f, test_acc: %.4f \n" % (
epoch, total_epochs, train_loss, train_acc, test_loss, test_acc)
print(line)
with open('logs.txt', 'a') as f :
f.write(line)
saver.save(sess=sess, save_path='./model/dense.ckpt')
一维代码
由于我做的是一维数据识别,需要将代码改为一维,和修改数据读入。
修改下面部分即可改变网络结构,由于电脑显卡太差,原论文中的结构会因为显存不够而报错。
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[1, 7], stride=2, layer_name='conv0')#卷积
x = Max_Pooling(x, pool_size=[1, 3], stride=2)#最大池化
for i in range(self.nb_blocks):
# 6 -> 12 -> 48
x = self.dense_block(input_x=x, nb_layers=2, layer_name='dense_' + str(i))
x = self.transition_layer(x, scope='trans_' + str(i))
"""
x = self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x = self.transition_layer(x, scope='trans_1')
x = self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x = self.transition_layer(x, scope='trans_2')
x = self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x = self.transition_layer(x, scope='trans_3')
"""
x = self.dense_block(input_x=x, nb_layers=4, layer_name='dense_final')
# 100 Layer
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
# x = tf.reshape(x, [-1, 10])
return x
完整代码
import tensorflow as tf
from tflearn.layers.conv import global_avg_pool
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.layers import batch_norm, flatten
from tensorflow.contrib.framework import arg_scope
import numpy as np
import matplotlib.pyplot as plt
# Hyperparameter
growth_k = 12
nb_block = 1 # how many (dense block + Transition Layer) ?
init_learning_rate = 1e-3
epsilon = 1e-8 # AdamOptimizer epsilon
dropout_rate = 0.2
# Momentum Optimizer will use
nesterov_momentum = 0.9
weight_decay = 1e-4
# Label & batch_size
class_num = 2
total_epochs = 400
DATA_SIZE = 1175
BATCH_SIZE =128
acc_print=[]
acc_printx=[]
acc_printy=[]
tf.reset_default_graph()
def conv_layer(input, filter, kernel, stride=1, layer_name="conv"):
with tf.name_scope(layer_name):
network = tf.layers.conv2d(inputs=input, filters=filter, kernel_size=kernel, strides=stride, padding='SAME')
return network
def Global_Average_Pooling(x, stride=1):
"""
width = np.shape(x)[1]
height = np.shape(x)[2]
pool_size = [width, height]
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride) # The stride value does not matter
It is global average pooling without tflearn
"""
return global_avg_pool(x, name='Global_avg_pooling')
# But maybe you need to install h5py and curses or not
def Batch_Normalization(x, training, scope):
with arg_scope([batch_norm],
scope=scope,
updates_collections=None,
decay=0.9,
center=True,
scale=True,
zero_debias_moving_mean=True):
return tf.cond(training,
lambda: batch_norm(inputs=x, is_training=training, reuse=None),
lambda: batch_norm(inputs=x, is_training=training, reuse=True))
def Drop_out(x, rate, training):
return tf.layers.dropout(inputs=x, rate=rate, training=training)
def Relu(x):
return tf.nn.relu(x)
def Average_pooling(x, pool_size=[1, 2], stride=2, padding='VALID'):
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Max_Pooling(x, pool_size=[1, 3], stride=2, padding='VALID'):
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Concatenation(layers):
return tf.concat(layers, axis=3)
def Linear(x):
return tf.layers.dense(inputs=x, units=class_num, name='linear')
class DenseNet():
def __init__(self, x, nb_blocks, filters, training):
self.nb_blocks = nb_blocks
self.filters = filters
self.training = training
self.model = self.Dense_net(x)
def bottleneck_layer(self, x, scope):
# print(x)
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch1')
x = Relu(x)
x = conv_layer(x, filter=4 * self.filters, kernel=[1, 1], layer_name=scope + '_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch2')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[1, 3], layer_name=scope + '_conv2')
x = Drop_out(x, rate=dropout_rate, training=self.training)
# print(x)
return x
def transition_layer(self, x, scope):
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope + '_batch1')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[1,1], layer_name=scope+'_conv1')
# https://github.com/taki0112/Densenet-Tensorflow/issues/10
#in_channel = x.shape[-1]
#x = conv_layer(x, filter=in_channel * 1, kernel=[1, 1], layer_name=scope + '_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Average_pooling(x, pool_size=[1, 2], stride=2)
return x
def dense_block(self, input_x, nb_layers, layer_name):
with tf.name_scope(layer_name):
layers_concat = list()
layers_concat.append(input_x)
x = self.bottleneck_layer(input_x, scope=layer_name + '_bottleN_' + str(0))
layers_concat.append(x)
for i in range(nb_layers - 1):
x = Concatenation(layers_concat)
x = self.bottleneck_layer(x, scope=layer_name + '_bottleN_' + str(i + 1))
layers_concat.append(x)
x = Concatenation(layers_concat)
return x
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[1, 7], stride=2, layer_name='conv0')#卷积
x = Max_Pooling(x, pool_size=[1, 3], stride=2)#最大池化
for i in range(self.nb_blocks):
# 6 -> 12 -> 48
x = self.dense_block(input_x=x, nb_layers=2, layer_name='dense_' + str(i))
x = self.transition_layer(x, scope='trans_' + str(i))
"""
x = self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x = self.transition_layer(x, scope='trans_1')
x = self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x = self.transition_layer(x, scope='trans_2')
x = self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x = self.transition_layer(x, scope='trans_3')
"""
x = self.dense_block(input_x=x, nb_layers=4, layer_name='dense_final')
# 100 Layer
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
# x = tf.reshape(x, [-1, 10])
return x
def convert_to_one_hot(Y, C): #转为1位热码编码
Y = np.eye(C)[Y.reshape(-1)].T
return Y
string0=np.loadtxt('4.30+5.1.txt',dtype=np.float32)
trainy=string0[:,0].reshape(-1,1).T #1行
trainx=string0[:,1:].reshape(1175,-1)
trainy= convert_to_one_hot(trainy.astype(int), 2).T
x = tf.placeholder(tf.float32, shape=[None, 500])
batch_images = tf.reshape(x, [-1,1,500,1])
label = tf.placeholder(tf.float32, shape=[None, 2])
training_flag = tf.placeholder(tf.bool)
learning_rate = tf.placeholder(tf.float32, name='learning_rate')
logits = DenseNet(x=batch_images, nb_blocks=nb_block, filters=growth_k, training=training_flag).model
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=label, logits=logits))
"""
l2_loss = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables()])
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=nesterov_momentum, use_nesterov=True)
train = optimizer.minimize(cost + l2_loss * weight_decay)
In paper, use MomentumOptimizer
init_learning_rate = 0.1
but, I'll use AdamOptimizer
"""
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, epsilon=epsilon)
train = optimizer.minimize(cost)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
tf.summary.scalar('loss', cost)
tf.summary.scalar('accuracy', accuracy)
saver = tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state('./model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path): #寻找模型路径
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
merged = tf.summary.merge_all() #合并默认图中收集的所有摘要。
writer = tf.summary.FileWriter('./logs', sess.graph) #指定一个文件用来保存图
global_step = 0
epoch_learning_rate = init_learning_rate
i=1
for epoch in range(total_epochs):
if epoch == (total_epochs * 0.5) or epoch == (total_epochs * 0.75):
epoch_learning_rate = epoch_learning_rate / 10
total_batch =10 #训练总次数
for step in range(total_batch):
start = (step * BATCH_SIZE) % DATA_SIZE
end = min(start + BATCH_SIZE, DATA_SIZE)
# 每次选取batch_size个样本进行训练
# _, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: trainx[start: end], y_: trainy[start: end]})
batch_x =trainx[start: end]
batch_y =trainy[start: end]
train_feed_dict = {
x: batch_x,
label: batch_y,
learning_rate: epoch_learning_rate,
training_flag: True
}
_, loss = sess.run([train, cost], feed_dict=train_feed_dict)
if epoch % 10 == 0:
global_step += 100
train_summary, train_accuracy = sess.run( [merged,accuracy], feed_dict=train_feed_dict)
#t_accuracy = sess.run(accuracy,feed_dict={x:batch_x,label:batch_y})
print("Step:", epoch, "Loss:", loss, "Training accuracy:", train_accuracy)
writer.add_summary(train_summary, global_step=epoch)
acc_print.append(train_accuracy)
acc_printy.append(loss)
acc_printx.append(i)
i+=1
test_feed_dict = {
x: trainx[start:end],
label: trainy[start:end],
learning_rate: epoch_learning_rate,
training_flag: False
}
#accuracy_rates = sess.run(accuracy, feed_dict=test_feed_dict)
#print('Epoch:', '%04d' % (epoch + 1), '/ Accuracy =', accuracy_rates)
# writer.add_summary(test_summary, global_step=epoch)
plt.title("trend of accuracy")
plt.plot(acc_printx,acc_print,color='r')
plt.plot(acc_printx,acc_printy,color='cyan')
plt.show()
saver.save(sess=sess, save_path='./model/dense.ckpt')
运行结果

不得不说还是很强大的。
参考连接
https://zhuanlan.zhihu.com/p/37189203

